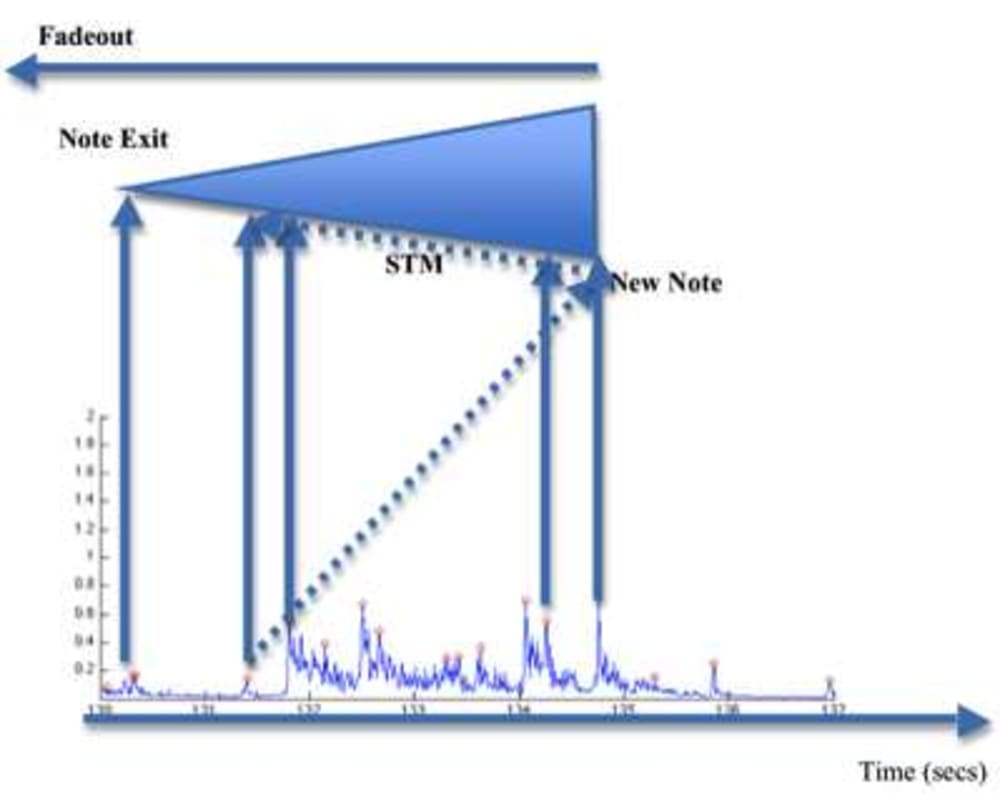





Audio feature estimation involves measuring key characteristics from the audio. It is possible to estimate features using an auditory memory model. In order to do so, an onset detection is necessary to identify new audio components to insert into the auditory memory, and an algorithm is necessary to combine the characteristics of the current interval with the characteristics of the audio components in the auditory memory. The auditory memory model mimics the attention process, and the storing, retrieval and forgetting processes. The feature estimation using the auditory memory model has been applied to the estimation of sensory dissonance. The feature estimation using the memory model is an important step in the improvement of the accuracy of feature estimation. Furthermore, the dissonance values are together with the characteristics of the auditory memory to be of interest in music categorization.
It is believed that feature estimation using the auditory memory model will bring the field significantly forward. The details of the auditory memory model consists of two parts. The onset detection can be compared to the attention human beings put on the sound. The memory model is based on the knowledge of the short-term memory, and contains a homogenous decay and displacement mechanism that calculates the activation strength of the components in the auditory memory as a function of the number of components in the memory model, and the total duration of the model. The memory model mimics the storing, retrieval and forgetting of the human auditory short-term memory.
Based on experiments, it is has been shown that the number of elements and duration behaves in a manner that is compatible with the human auditory short-term memory in the current state of knowledge.
As the sensory dissonance is shown to be additive for partials in the same time frame, it is here modeled additive also for the partials that belong to the auditory components in the memory. These partials are thus modeled as giving rise to beats together with the partials in the current time frame. The resulting sensory dissonance is shown to be more smooth, and having a larger magnitude.
Both the characteristics of the auditory memory model, with regards to the duration and number of components, and the sensory dissonance calculated using the model, are shown to be informative about the song the features are obtained from. For instance, pop songs typically contains more auditory components in the memory model, and jazz songs have longer durations of the memory. Furthermore, the dissonance of the pop songs are much higher than the dissonance of the jazz songs. It seems promising to use the auditory memory model, and the sensory dissonance calculated using it, for music information retrieval purposes.
It has furthermore been shown that the sensory dissonance calculated using the auditory memory model performs significantly better than the sensory dissonance calculated without the memory model when compared to human dissonance assessment.
Like this entry?
-
About the Entrant
- Name:Kristoffer Jensen
- Type of entry:individual
- Software used for this entry:matlab
- Patent status:pending